|
|
 |
|
Calanoida ( Order ) |
|
|
|
Clausocalanoidea ( Superfamily ) |
|
|
|
Euchaetidae ( Family ) |
|
|
|
Paraeuchaeta ( Genus ) |
|
|
| |
Paraeuchaeta tumidula (Sars, 1905) (F,M) | |
| | | | | | | Syn.: | Euchaeta tumidula Sars, 1905 b (p.15); Vervoort, 1957 (p.78); Harding, 1974 (p.141, tab. 3, gut contents);
Pareuchaeta pseudotumidula Brodsky, 1950 (1967) (p.217, figs.F,M, Rem.); Yamaguchi & al., 2002 (p.1007, tab.1); Ikeda & al., 2006 (p.1791, Table 2);
Pareuchaeta tumidula : Sars, 1925 (p.119, figs.F); Wilson, 1942 a (p.201); C.B. Wilson, 1950 (p.285); Heptner, 1971 (p.108, figs.F,M);
Euchaeta biconvexa Park, 1978 (p.264, figs.F,M) | | | | Ref.: | | | Bradford & al., 1983 (p.23, 28, Rem.); Park, 1994 (p.322); 1995 (p.82, figs.F,M); Vives & Shmeleva, 2007 (p.672, figs.F,M, Rem.) | 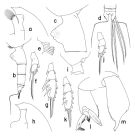 issued from : T. Park in Bull. Scripps Inst. Oceanogr. Univ. California, San Diego, 1995, 29. [p.189, Fig.79]. Female: a, forehead (left side); b, urosome (left); c, genital somite (left); d, distal end of urosome (dorsal); e, outer lobe of Mx1; f, exopod of P1 (anterior); g, exopod of P2 (anterior). Nota: Distal end of prosome on each side broadly rounded. Cephalosomal appendages as in P. glacialis except that outer lobe of Mx1 with 6 long setae plus 1 minute seta proximally. In P1 exopod, outer spine of 1st segment small; that of 2nd segment extending beyond base of following outer spine by about 1/4 its length. Genital flange nearly triangular, with long, convex anterior side and short, steep posterior side; medial margin of genital flange emarginate and thereby flange is divided into anterior and posterior lobes; posterior edge of genital field produced distally into distinct tubercular outgrowth. Male: h, forehead (left); i, last pedigerous and genital somites (left); j, exopod of P1 (anterior); k, exopod of P2 (anterior); l, distal exopodal segments of left 5th leg (medial, tilted clockwise); m, serrated lamella of left 5th leg exopod (lateral, tilted clockwise). Nota: Cephalosomal appendages similar to those of P. malayensis, P. glacialis
|
 issued from : T. Park in Antarctic Res. Ser. Washington, 1978, 27. [p.265, Fig.108]. As Euchaeta biconvexa. Female: A, habitus (lateral); B, forehead (lateral); C, D, E, F, distal end of metasome and genital segment (dorsal, ventral, left side, and right side, respectively); G, outer lobe of Mx1; H, P1; I, P2. P1-2: legs (anterior). Nota from Bradford & al. (1983, p.28): - P1 exopod: Aa < 1/3 AB; Bb > BC; Cc > 1.1/2 BC. - P2 exopod: Aa = AB + 3/4 Bb; Bb = BC + 1/3 Cc; Cc < CD. (see code of lengths outer spine in the Genus' figure of Paraeuchaeta, or in Paraeuchaeta sp. A Bradford, 1981).
|
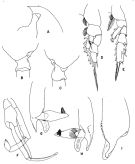 issued from : T. Park in Antarctic Res. Ser. Washington, 1978, 27. [p.266, Fig.109]. As Euchaeta biconvexa. Male: A, forehead (lateral); B, C, distal end of metasome and genital segment (left side and right side, respectively); D, P1; E, P2; F, P5; G, H, I, distal part of exopod of left P5 (posterior, anteromedial, and anterolateral, rspectively). P1-5: legs (anterior). Nota from Bradford & al. (1983, p.28): - P1 exopod: Aa minute; Bb < 1/2 BC; Cc ± 4/5 BC. - P2 exopod: Aa < 1/2 AB; Bb ± 1/2 BC; Cc < 1/2 CD. (see code of lengths outer spine in the Genus' figure of Paraeuchaeta, or in Paraeuchaeta sp. A).
|
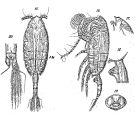 Issued from : G.O. Sars in Résult. Camp. Scient. Prince Albert I, 69, pls.1-127 (1924). [Pl.XXXII, figs.15-20]. As Pareuchaeta tumidula. Female: 15, habitus (dorsal); 16, idem (lateral left side); 17, forehead (lateral); 18, genital somite (lateral left side); 19, genital complex (ventral); 20, anal segment and caudal rami.
|
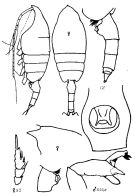 Issued from : K.A. Brodskii in Calanoida of the Far Eastern Seas and Polar Basin of the USSR. Opred. Fauna SSSR, 1950, 35 (Israel Program for Scientific Translations, Jerusalem, 1967) [p.217, Fig.130]. As Pareuchaeta pseudotumidula. Female (from NW Pacif.): habitus (dorsal and lateral left side); forehead (lateral); S2, exopod of P2; corner of the last thoracic segment and urosome (lateral left side); genital segment (lateral right side); Gf, genital segment (ventral). Male: S5Le, distal segments of left P5. Nota: This form resembles P. tumidula but differs in its size, the shorter genital segment and caudal rami.
|
 issued from : M.V. Heptner in Trudy. Inst. Okeanol., 1971, 92. [p.109, Fig.17]. As Pareuchaeta tumidula. Female (from Kuril-Kamchatka Trench).. Nota: Formula of the exopod of P1 spines on the last two segments, successively : Aa < AB (Aa < 1/2 AB); Bb > BC (Bb = 1 1/4 BC); Cc > BC (Cc ≈ 1 1/2 BC); variant: Aa < 1/4 AB, Aa = 1/2 AB, Aa = 2/3 AB; Bb = BC. P2: Aa > AB (Aa = AB + 1/2 Bb); Bb = BC; Cc < CD (Cc ≈ 7/8 CD). Variant: Aa = AC, Aa = AB + 2/3 Bb; Bb < BC (Bb = BC + 1/4 Bb). [cf. legend in drawings of Heptner, 1971, for Pareuchaeta rubra].
Male: ld, left exopod portion of P5.
|
 Paraeuchaeta tumidula Female: 1 - See key to species Groups and independent species of Paraeuchaeta (p.30). 2 - Appendicular caudal setae geniculated, extending laterad far beyond lateral side of caudal rami before curving backward (Fig.79-b, d).
| | | | | Compl. Ref.: | | | Sewell, 1948 (p.348, 501, 566, 569); Razouls & al., 2000 (p.343, Appendix); Park & Ferrari, 2009 (p.143, Table 4, Appendix 1); | | | | NZ: | 9 | | |
|
Distribution map of Paraeuchaeta tumidula by geographical zones
|
| | | | | | | | | | Loc: | | | Antarct. (SW Pacif.), sub-Antarct. (SE Pacif.), off E Cape Cod, off NW Canary Islands, Azores, Okhotsk Sea, Kuril-Kamchatka Trench, Station Knot, Philippines, China Seas (Taiwan), Japan, off N California, off Galapagos, off Peru | | | | N: | 10 | | | | Lg.: | | | (1) F: 3,3; (3) F: 4,8-4,04; M: 3,88; (20) F: 4,44-4,24; M: 4,2; (22) F: 4,7-4; M: 4,2; (23) F: 4,9-4,15; M: 4,65-4,4; {F: 3,30-4,90; M: 3,88-4,65}
The mean female size is 4.856 mm (n = 9; SD = 0.4964), and the mean male size is 4.266 mm (n = 5; SD = 0.2842). The size ratio (male : female) is 0.953 (n = 4; SD = 0.0519), or ± 95 %. | | | | Rem.: | bathy-abyssopelagic.
Sampling depth (Antarct. sub-Antarct.): 0-2000 m. Kuril-Kamchatka Trench: 1000-4000 m). In vertical tow 4000-3000 m (Harding, 1974).
Park (1995, p.83) found this species in the northeastern Atlantic at 47°N (close to the type locality), the eastern tropical Pacific close to Central America, off northern California, and off the Pacific coast of northern Japan at 33°N and 35°N. | | | Last update : 12/08/2016 | |
|
|
 Any use of this site for a publication will be mentioned with the following reference : Any use of this site for a publication will be mentioned with the following reference :
Razouls C., Desreumaux N., Kouwenberg J. and de Bovée F., 2005-2025. - Biodiversity of Marine Planktonic Copepods (morphology, geographical distribution and biological data). Sorbonne University, CNRS. Available at http://copepodes.obs-banyuls.fr/en [Accessed November 30, 2025] © copyright 2005-2025 Sorbonne University, CNRS
|
|
|
|



;)
;)
;)
;)
;)
;)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}